Abstract
Occupancy is crucial for autonomous driving, providing essential geometric priors for perception and planning. However, existing methods predominantly rely on LiDAR-based occupancy annotations, which limits scalability and prevents leveraging vast amounts of potential crowdsourced data for auto-labeling. To address this, we propose GS-Occ3D, a scalable vision-only framework that directly reconstructs occupancy. Vision-only occupancy reconstruction poses significant challenges due to sparse viewpoints, dynamic scene elements, severe occlusions, and long-horizon motion. Existing vision-based methods primarily rely on mesh representation, which suffer from incomplete geometry and additional post-processing, limiting scalability. To overcome these issues, GS-Occ3D optimizes an explicit occupancy representation using an Octree-based Gaussian Surfel formulation, ensuring efficiency and scalability. Additionally, we decompose scenes into static background, ground, and dynamic objects, enabling tailored modeling strategies: (1) Ground is explicitly reconstructed as a dominant structural element, significantly improving large-area consistency; (2) Dynamic vehicles are separately modeled to better capture motion-related occupancy patterns. Extensive experiments on the Waymo dataset demonstrate that GS-Occ3D achieves state-of-the-art geometry reconstruction results. By curating vision-only binary occupancy labels from diverse urban scenes, we show their effectiveness for downstream occupancy models on Occ3D-Waymo and superior zero-shot generalization on Occ3D-nuScenes. It highlights the potential of large-scale vision-based occupancy reconstruction as a new paradigm for scalable auto-labeling.
Motivation
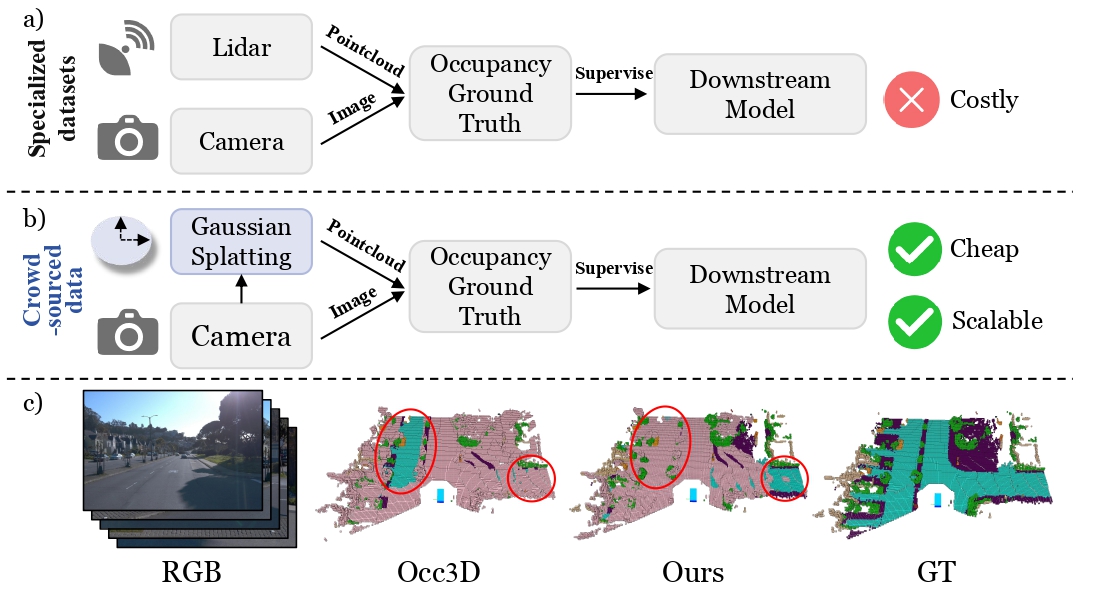
(a) Existing methods predominantly rely on LiDAR-based occupancy annotations, requiring costly specialized surveying vehicles, which significantly limits scalability.
(b) In contrast, GS-Occ3D introduces a scalable, vision-only occupancy reconstruction framework that effectively harnesses abundant crowdsourced data from consumer-grade vehicles for auto-labeling. Our approach enables affordable and scalable curation of high-quality occupancy labels.
(c) We present an overlay of the binary prediction (pink) and the Occ3D-Waymo validation GT (other colors represent semantics), solely to visualize areas where the predictions are incomplete. Comparing models trained with two types of labels, we achieve generally comparable or even better generalization geometry results in certain setups.
Method Overview
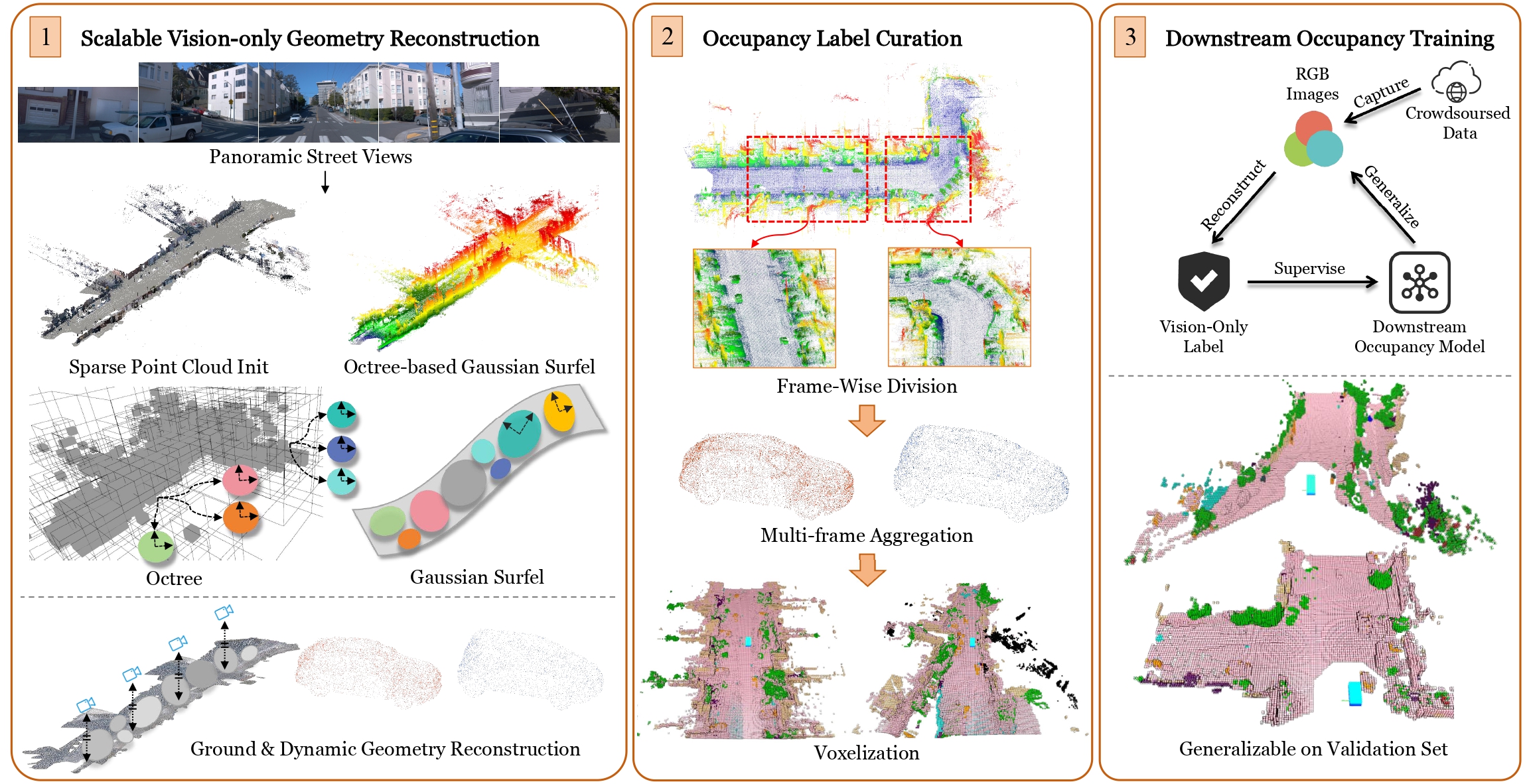
Overview of the GS-Occ3D. Left: Panoramic street views captured along long trajectories are used to generate a sparse point cloud and ground surfels as initialization. We adopt an Octree-based Gaussian Surfel representation that integrates ground, background, and dynamic objects to achieve scalable vision-only geometry reconstruction. Here, we present an uphill scene with colors indicating height.
Middle: Given the vision-only point cloud, our label curation pipeline applies frame-wise division and multi-frame aggregation to define appropriate perception ranges per frame, while increasing point cloud density, especially for dynamic objects with incomplete observations. Ray-casting is then applied to each frame to determine voxel occupancy, explicitly handling occlusions from the camera’s viewpoint.
Right: The resulting vision-only labels can be used to train downstream occupancy models, enabling these models to generalize to unseen scenes with geometric reasoning capability. Pink indicates the binary voxel, while other colors represent Occ3D labels.
Results
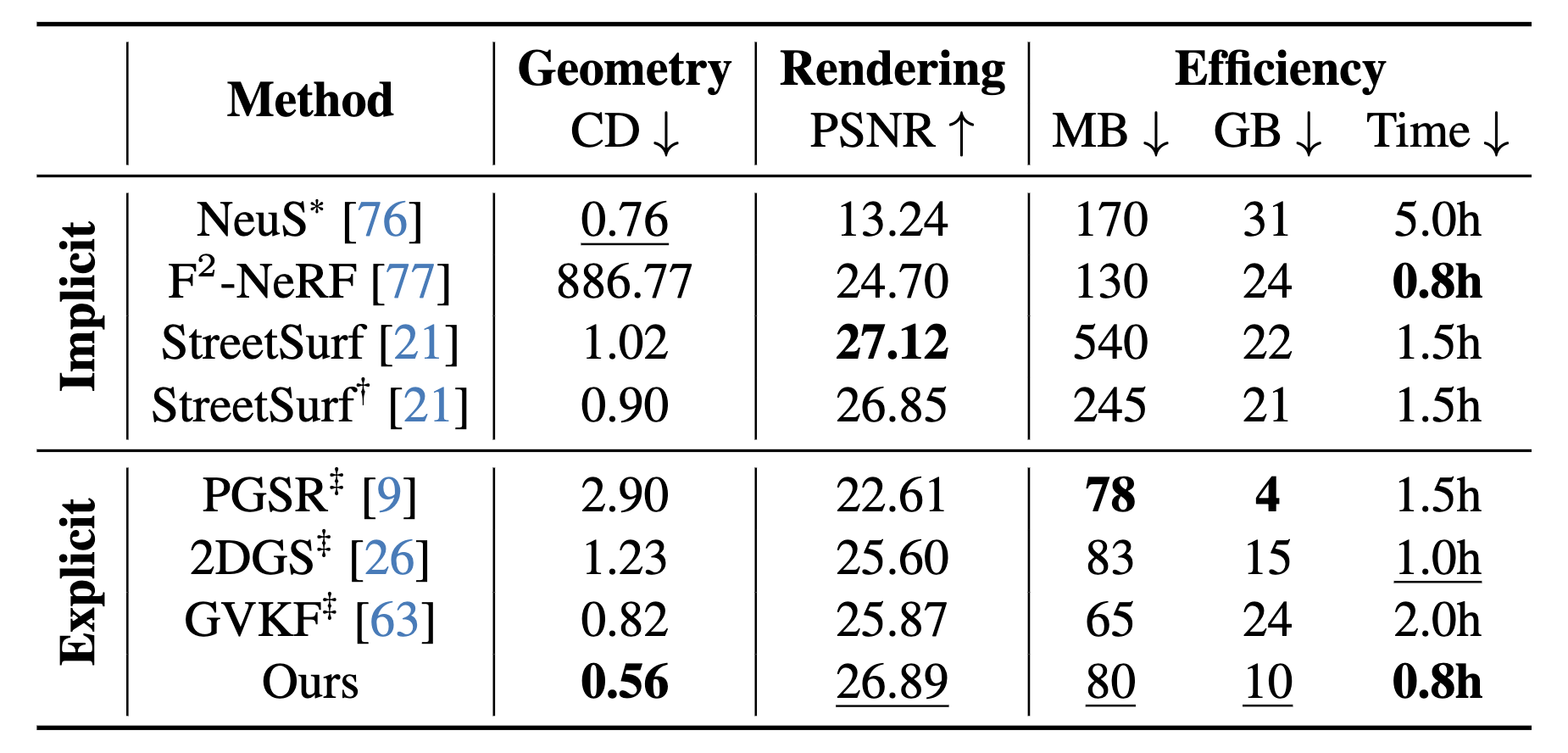
SOTA Geometry Reconstruction on Waymo
NeuS* uses 1 dense and 4 sparse LiDARs, StreetSurf† uses 4 sparse LiDARs, and all other methods are vision-only. ‡ indicates using our ground gaussians. MB indicates storage size, GB indicates GPU memory, and Time indicates training time.
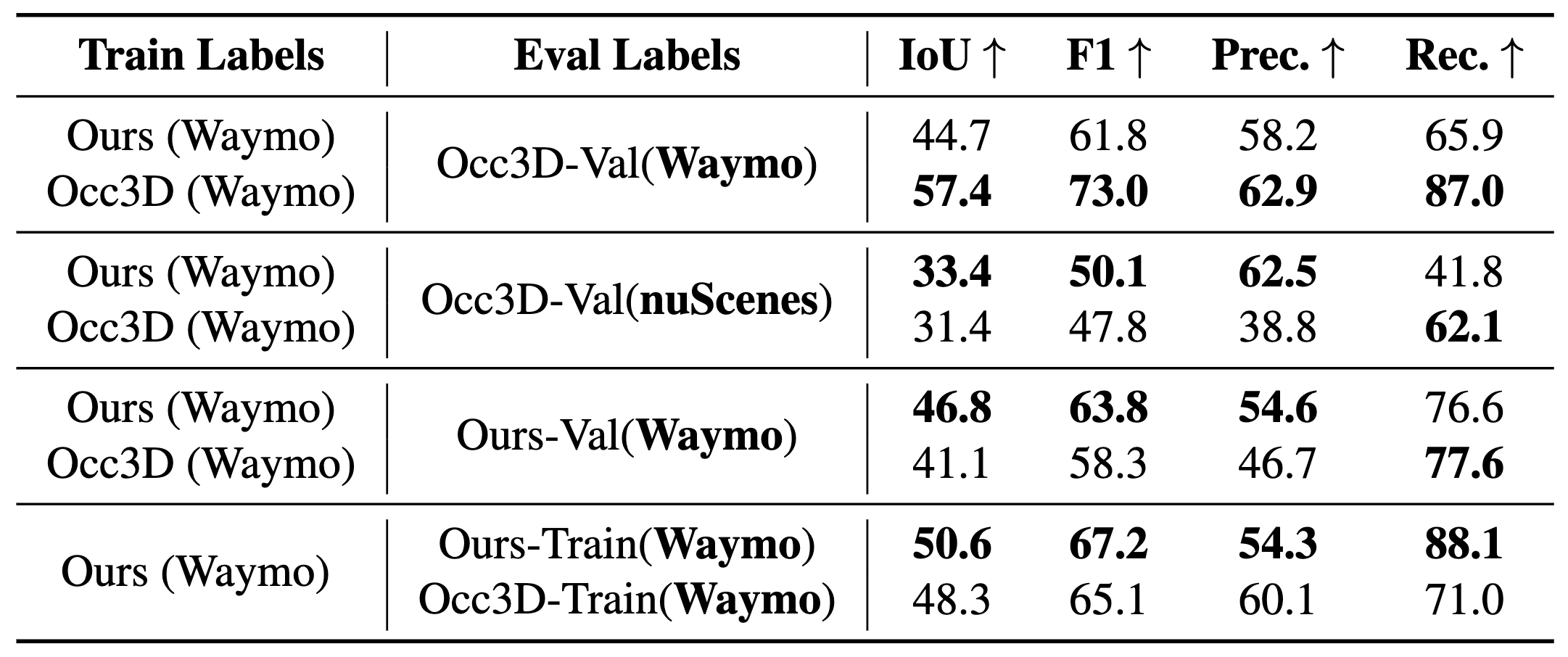
Occupancy Generalization and Fitting Results on the Occ3D Dataset
Generalization and Fitting Results on the Occ3D Dataset for SOTA occupancy model CVT-Occ under different training and evaluation label combinations.
Visualization
Visualization of Geometry Reconstruction on Waymo
The color represents CD with respect to LiDAR, ranging from blue (lower CD) to red (higher CD). Our method exhibits improved reconstruction fidelity in weakly-textured regions compared to other methods, while maintaining structural completeness comparable to LiDAR point cloud, even in the absence of geometric priors.

Detailed Geometry
We present the detailed geometry of the red-boxed area in the figure above, achieving results that are both comparable and complementary to LiDAR. The first row is uphill, while the second is downhill followed by uphill.

Curated Labels
We achieve globally comparable geometry to Occ3D, ensuring reliable supervision for occupancy model training without priors.

Occupancy Generalization Results
We evaluate the SOTA occupancy model CVT-Occ trained with our labels and Occ3D, achieving reasonable and overall comparable results.
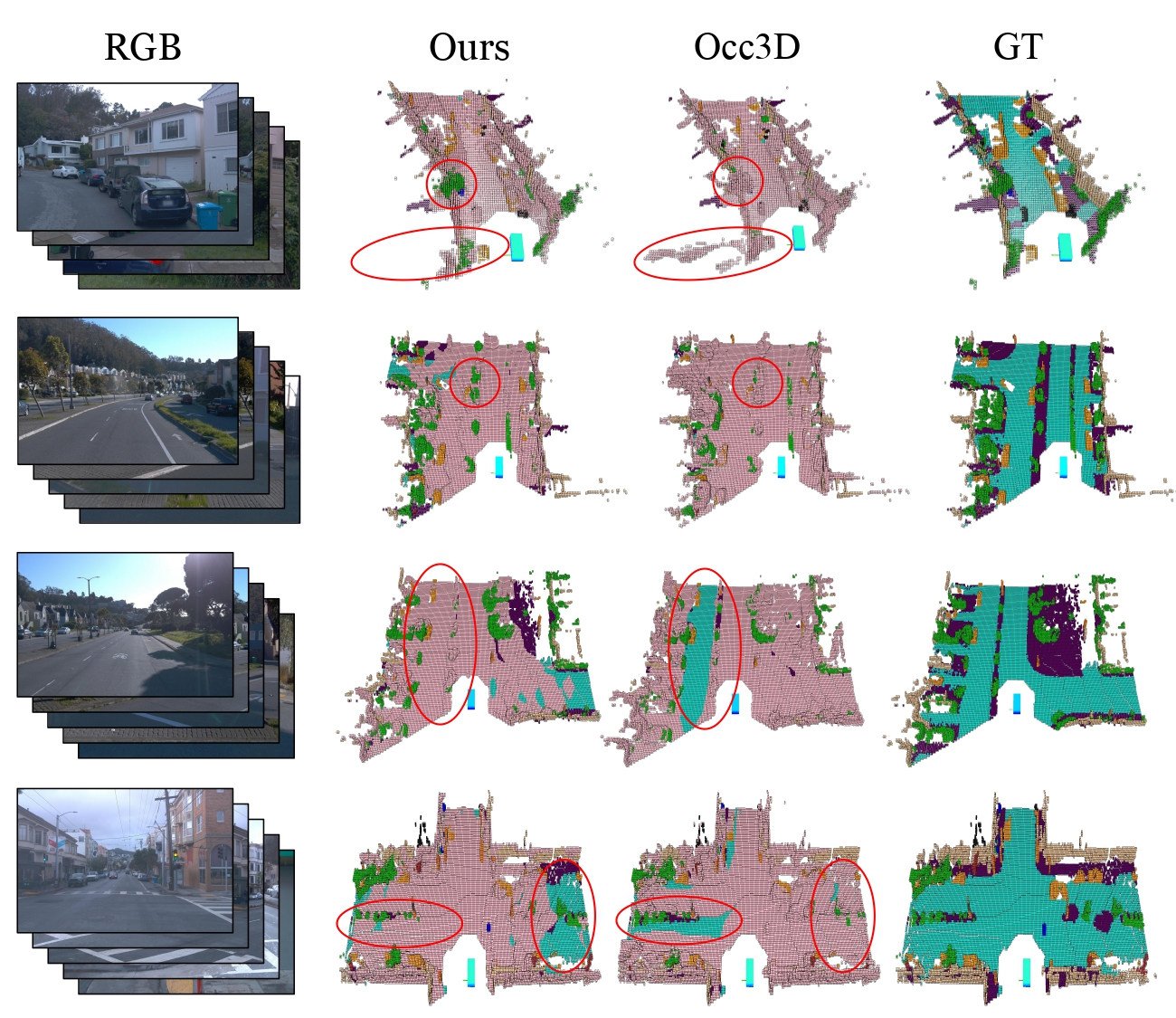
More Visualization
Up: Richer semantic labels. Down: superior generalization on Occ3D-nuScenes. Pink indicates binary prediction, others show errors.
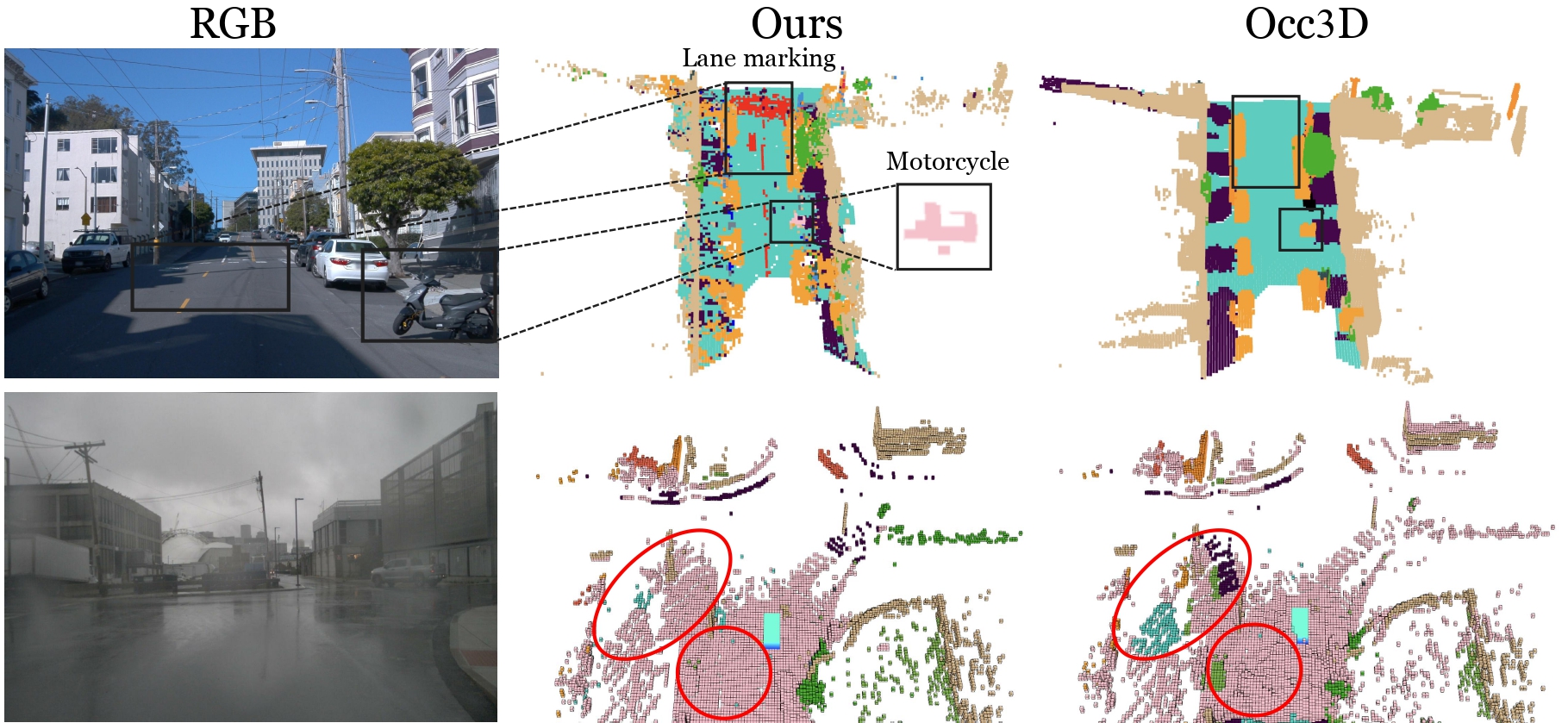
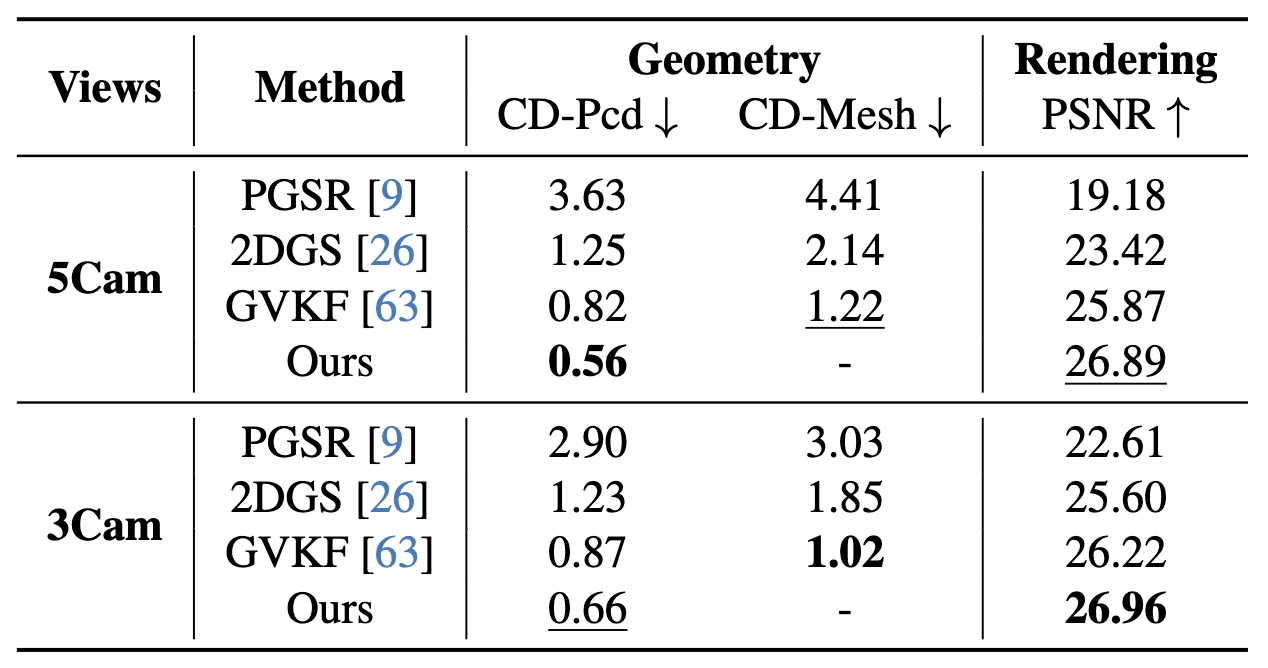
Ablation Study
Ablation Studies on Waymo Static-32 Split
We evaluate varying camera counts and representations. All methods use our Ground Gaussians for fairness. Both chamfer distance of the point cloud and mesh are measured against LiDAR.
Ground Gaussians
We show the effectiveness of our ground gaussians. Colors indicate height, ranging from blue to red.

BibTeX
@article{GS-Occ3D,
title={GS-Occ3D: Scaling Vision-only Occupancy Reconstruction with Gaussian Splatting},
author={Baijun Ye and Minghui Qin and Saining Zhang and Moonjun Goon and Shaoting Zhu and Zebang Shen and Luan Zhang and Lu Zhang and Hao Zhao and Hang Zhao},
journal={arXiv preprint arXiv:2507.19451},
year={2025}
}